
Сейчас происходит стремительный подъем голосовых технологий. Их потенциал действительно огромный, особенно в текущее коронавирусное время, когда мы вынуждены соблюдать различные меры предосторожности, в том числе социальную дистанцию.
Google, Amazon и другие технические гиганты уже успели обзавестись виртуальными помощниками: их продукты умеют не только слушать, но и слышать, понимать, а потом отвечать на запрос пользователя. Архитектура таких приложений очень сложная, но в ее основе всегда лежит один принцип – преобразование человеческой речи в текст.

Итак, как же научить свое веб-приложение слышать пользователей? Давайте разбираться.
.
Принцип работы
Google Chrome сам по себе не наделен функцией распознавания человеческой речи. Расшифровка происходит на серверах компании, куда браузер отправляет аудио-файлы, а потом получает обратно результат. Подробнее об этом можно узнать .
Из-за использования API на серверной части, пользователи SpeechRecognition должны быть в онлайне. Это ограничение, к сожалению, не исчезнет до тех пор, пока в Google не будет реализовано локальное распознавание.
Приступаем к созданию
Давайте поставим перед собой такую задачу - создать HTML-код с полем для ввода информации и кнопкой для распознавания речи пользователей. Обратите внимание, что прослушивание не должно начинаться сразу после того, как страница загрузится: сперва нужно получить согласие пользователя на использование такой возможности.
Вид конечного результата довольно простой:
Нам нужно добавить фрагмент JS-кода, который отвечает за распознавание речи, а затем мы сами же его протестируем! Находиться следующие строки должны в теге script элемента body.
Для прослушивания и дальнейшего преобразования человеческой речи в текстовый вид нам больше ничего не нужно. А сейчас начнем разбираться с JavaScript-кодом.
Переходим на строку 2 и создаем API-экземпляр webkitSpeechRecognition. Далее прописываем булевую переменную, которая принимает одно из двух значений: «прослушивать» или «не прослушивать».
Следующим шагом определяем три функции:
- start,
- stop,
- onResult.
Они меняют текст нашей кнопки в зависимости от правильного состояния и начинают либо же останавливают процесс распознавания. Третья функция также формирует итог распознавания и демонстрирует его пользователю.
После запуска кода и нажатия кнопки для начала прослушивания вам нужно будет подтвердить согласие на использование микрофона – только после этого Chrome начнет слушать, что вы говорите.
По завершении в консоли разработчика появится SpeechRecognitionEvent. Давайте проанализируем это событие.
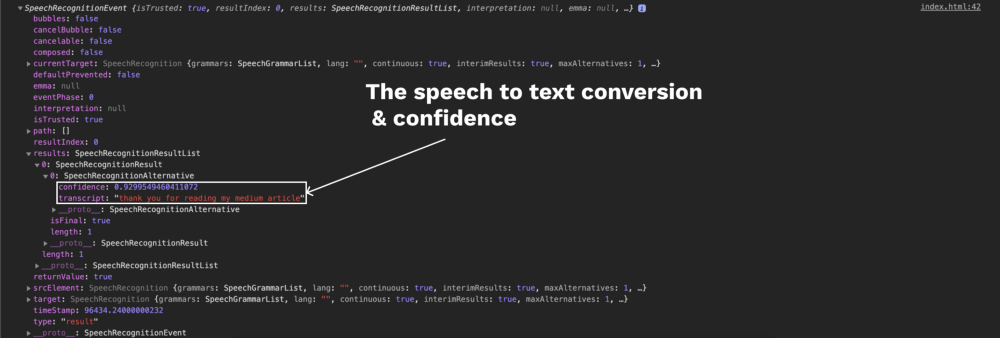
Важнейшим свойством здесь является results – список объектов-результатов (SpeechRecognitionResult). В нашем случае он будет всего один, поскольку мы сказали только 1 фразу до остановки прослушивания.
В объекте результата находится перечень объектов SpeechRecognitionAlternative. Первый включает расшифровку сказанного, а также степень уверенности, которая может принимать значения в диапазоне 0-1. Эта цифра позволяет определить наиболее правильную расшифровку среди имеющихся вариантов.
Можно получать и сразу несколько объектов в SpeechRecognitionAlternative. К примеру, если вам хочется, чтобы пользователи сами определяли лучший вариант.
Теперь разберем, за что отвечает recognition.continuous:
- recognition.continuous = true, результаты идут друг за другом;
- recognition.continuous=false, есть только один-единственный результат.
Какие результаты должна возвращать система – промежуточные или окончательные – определяется recognition.interimResults.
С задачей распознавания слов и их сочетаний API справляется очень хорошо. Намного хуже складывается картина с пунктуацией.
Браузерная поддержка
Пока распознавание речи с помощью Web Speech API поддерживается только Chrome для PC и ОС Android (заметьте, что мы применяем webkitSpeechRecognition).