
Какие невероятные возможности открываются перед человеком при правильном и разумном применении машинного обучения, нейронных сетей и искусственного интеллекта в целом.
Обычный человек даже не замечает как часто и много он сталкивается с различного рода искусственным интеллектом в повседневной жизни. На самом деле, машинное обучение повсюду: в голосовых помощниках (Siri, Алекса, Кортана), на сайтах, в соц сетях, машинах и даже в том же Google переводчике. Там он используется, чтобы в случае непонимания слова перевести его на любой доступный язык, а далее с того языка переводить на искомый вариант. Это дает им возможность создать переводчик практически для всех языков мира.
При этом всем, до сих пор может показаться, что нейронные сети и машинное обучение где-то далеко, где-то в Калифорнии или в в скрытых штаб-квартирах компаний Google, Tesla, Apple и прочих.
В ходе статьи мы рассмотрим основные положения искусственного интеллекта и постараемся создать свою нейронную сеть на основе языка Python.
Искусственный интеллект
Ни для кого не секрет, что ИИ появился еще в середине прошлого столетия – в 1956 году. Тогда появилась сама концепция этой технологии, были описаны основные парадигмы и принципы. В те времена разработать ИИ не представлялось возможным, ведь тогдашние компьютеры были не мощнее современных калькуляторов, а, собственно, про какой ИИ может идти речь на калькуляторе?
Первый крупный прорыв состоялся в 1996 году. Тогда программа компании IBM обыграла чемпиона по шахматам Гарри Каспарова. Полноценным ИИ это сложно было назвать, ведь шахматы имеют конечное количество возможных ходов и программе необходимо было обладать знаниями обо всех возможных исходах, чтобы предсказать выигрышную стратегию для себя.

Следующий важный прорыв случился уже в 2016 году. Тогда программа AlphaGo компании Google DeepMind обыграла чемпиона мира по Го – Ли Седоля. Это стало важным событием, ведь в Го неограниченное или практически неограниченное количество возможных решений. Здесь в силу вступило машинное обучение, которое не оперировалось на всех возможных комбинациях игры, а оперировалось на основе своих собственных предположений, весов, которые подсказывали как стоит походить в разного рода ситуациях.
Это звучит как действительно настоящие компьютерные мозги, но насколько живи эти мозги? В статье мы еще подберемся к теме обучения нейронной сети, но пока лишь стоит сказать, что подобные программы основываются на достаточно простом для понимания принципе. В программу мы даем различные условия и говорим что при одном условии, будет выигрыш, а при другом - проигрыш. Обучив нейронку тысячами таких примеров она способна сама взвесить входные данные и понять к какому ответу они больше похожи - к выигрышному или наоборот.
Машинное обучение и глубокое обучение
Машинное обучение – это процесс обучения нейронной сети. Обучение, если говорить простыми словами, проходит за счёт указания нескольких вариантов одного решения, а затем нескольких вариантов другого. Далее нейронная система будет иметь некие весы для взвешивания новых задач и будет определять какое значение мы ей предлагаем.
Глубокое обучение – это подмножество машинного обучения. Оно является более дорогим и обучение проходит на гораздо большем массиве данных.
Получается следующая иерархия: есть нейронные сети, которые требуется обучить, выполнить машинное обучение или глубокое обучение. После их обучения мы получаем искусственный интеллект, что способен сам решать поставленные перед ним задачи.
Задача классификации
Теперь рассмотрим нейронную сеть на примере задачи классификации. Нейронные сети способны решать множество задач, мы же рассмотрим наиболее простую из них – задачу классификации. Суть задачи состоит в классификации объекта к определенной группе. Например, мы рисуем число 0, а нейронка должна понять что это за число. Другой пример, мы указываем характеристики автомобиля, а нейронка исходя из описания классифицирует машину и говорит её название.
В любой нейронке есть входные сигналы. Это те характеристики что мы с вами указываем, например, описание автомобиля. На основе этих данных нейронная сеть должна понять какой это автомобиль. Чтобы сделать решение она должна взвесить предоставленные данные и для этого используются, так называемые, весы. Это дополнительные числа, на которые в последствии будут умножены входные сигналы.
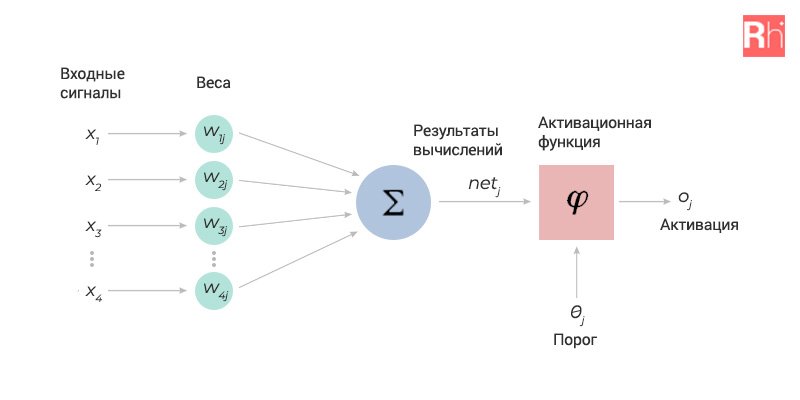
После умножения все данные суммируют, добавляется число корреляции и далее результат сравнивают с неким числом. Если итог более числа 0, то можно предположить, что машина, к примеру, Mercedes, а если менее 0, то это будет, например, BMW.
Мы рассмотрели работу лишь одного нейрона. Обычно для задач используется сеть нейронов, то есть объединение нескольких нейронов, где каждый из них решает какую-либо свою небольшую задачу.
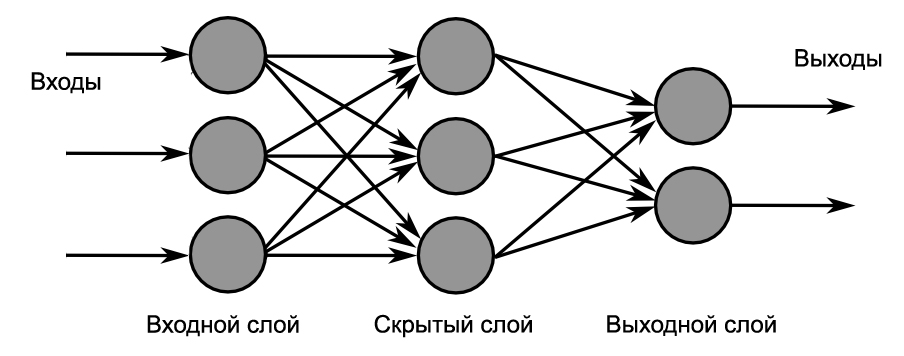
Первый слой нейронов может решить несколько своих небольших задач и дать нам ответы. Далее на основе ответов формируется второй слой нейронов, скрытый слой, который также решает задачи и дает ответы. Таких слоев может быть множество и чем их больше, тем сложнее нейронная сеть. В конечном результате мы получаем множество взвешенных решений и на их основе спокойно можем вынести вердикт. В нашем примере нейронка могла бы сказать к какой марке относиться автомобиль.
Почем Python?
На самом деле, вы можете использовать любые языки для этой цели. Можно писать ИИ используя: JavaScript, Java, Go и так далее. Питон не гласно принят одним из лидеров этой сфере по причине своей распространенности, известности и огромного множества библиотек, что обладают набором встроенных математических функций для решения задач внутри нейронной сети.
Мы тоже будем использовать Питон, но знайте, что такое можно написать и без использования библиотек, а соответственно можно писать хоть на PHP, хоть на C#. Нет смысла писать математические функции самому по типу Сигмоида, функция получения случайного числа и тому подобных. По этой причине мы будем использовать Python и библиотеку numpy.
Разработка нейронной сети
Полная разработка проекта показывается в видео. Вы можете просмотреть его ниже:
Код для реализации простой нейронной сети:
import numpy as np
# Функция сигмоида
# Необходима для опредления значения весов
def sigmoid(x, der=False):
if der:
return x * (1 - x)
return 1 / (1 + np.exp(-x))
# Набор входных данных
x = np.array([[1, 0, 1],
[1, 0, 1],
[0, 1, 0],
[0, 1, 0]])
# Выходные данные
y = np.array([[0, 0, 1, 1]]).T
# Сделаем случайные числа более определёнными
np.random.seed(1)
# Инициализируем веса случайным образом со средним 0
syn0 = 2 * np.random.random((3, 1)) - 1
l1 = []
for iter in range(10000):
# Прямое распространение
l0 = x
l1 = sigmoid(np.dot(l0, syn0))
# Насколько мы ошиблись?
l1_error = y - l1
# Перемножим это с наклоном сигмоиды
# на основе значений в l1
l1_delta = l1_error * sigmoid(l1, True)
# Обновим веса
syn0 += np.dot(l0.T, l1_delta)
print("Выходные данные после тренеровки:")
print(l1)Изучение программирования
А вы хотите стать программистом и начать разрабатывать самостоятельно ИИ или хотя бы использовать уже готовые для своих собственных проектов? Предлагаем нашу программу . В ходе программы вы научитесь работать с языком, изучите построение мобильных проектов, научитесь создавать полноценные веб сайты на основе фреймворка Джанго, а также в курсе будет модуль по изучению нескольких готовых библиотек для искусственного интеллекта.